⚠️ Update!
Troy Hunt recently released V2 of HIBP Passwords and removed the API rate limits, so you're probably better off using that service than setting up your own copy.Troy Hunt recently introduced HIBP Passwords, a freely downloadable list of over 300 million passwords that have been pwned in the various breaches the site records. There is an API to access the list for auditing and checking passwords, but it's rate limited, and I thought it would be more friendly to import the passwords in to a database we control. It looks like HIBP uses Azure Table Storage to make the data quickly accessible, I do most of my work on AWS so I thought I'd take a look at importing the hashes in to DynamoDB. It's relatively cheap to run and easy to use. I thought it might be useful for others, so here's the rundown.
The first thing I tried was to follow a tutorial using AWS Data Pipeline, which seemed to be exactly what I needed. In the end though, I found the tutorial made a few assumptions that I either missed or they failed to mention, mostly around the expected data format for the CSV files. Thankfully though, this lead me towards using AWS Elastic Map Reduce directly and this turned out to be the winning formula.
To start with, I needed to get the data from HIBP and upload it to S3. I think this method would have worked if the source files had been gzipped, but I wasn't too sure about 7zipped, so I decompressed them before uploading them to S3.
mkdir hibp-passwords
cd hibp-passwords
wget https://downloads.pwnedpasswords.com/passwords/pwned-passwords-1.0.txt.7z
wget https://downloads.pwnedpasswords.com/passwords/pwned-passwords-update-1.txt.7z
wget https://downloads.pwnedpasswords.com/passwords/pwned-passwords-update-2.txt.7z
7zr e pwned-passwords-1.0.txt.7z
7zr e pwned-passwords-update-1.txt.7z
7zr e pwned-passwords-update-2.txt.7z
rm *.7z
aws s3 mb s3://hibp-passwords-123
aws s3 sync ./ s3://hibp-passwords-123
I created a DynamoDB table to hold the data. It only needs the one column, which will also be the partition key.
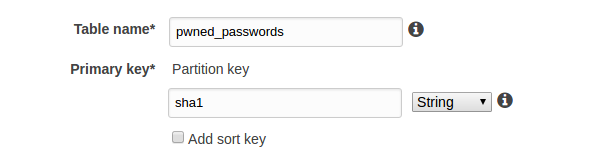
Now adjust the write capacity to allow our import to go reasonably quickly. I set the capacity to 10000 units, which I think was the maximum without having to asking AWS to lift the limits.

We then need to create our EMR cluster. I experimented with different sizes to begin with, but settled on a cluster of 16 c4.8xlarge instances. I left the rest of the settings as the defaults. Between this and the write capacity we set on the DynamoDB table, this meant the import took around 16 hours. There's probably a better combination of cluster size and write capacity, but it was good enough for me. I should point out here that this isn't a cheap way to do this, I think the work of this EMR cluster will come to around $400. I imagine someone who knows what they are doing with Hadoop/Hive/etc, could do this much more efficiently.

Now we're all good to go. Log in to the EMR master node, install tmux and fire up Hive.
ssh -i ~/.ssh/your-key.pem hadoop@your-master-node-public-url
sudo yum install tmux
tmux
hive
We need to tell Hive to use as much DynamoDB write capacity as it sees fit, no other resources are currently trying to access the table.
> SET dynamodb.throughput.write.percent=1.5;
We then create our first Hive table, by telling it where to find our data.
> CREATE EXTERNAL TABLE s3_hibp_passwords(a_col string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION 's3://hibp-passwords-123/';
OK
Time taken: 3.371 seconds
The first time I tried running the import, I ran in to trouble with it trying to enter duplicate items in to the DynamoDB table. A bit of searching lead me to a stackoverflow question and a means to create another table, but with only unique hashes.
> CREATE TABLE s3_hibp_passwords_dedup AS
SELECT a_col
FROM (SELECT a_col, rank() OVER
(PARTITION BY a_col)
AS col_rank FROM s3_hibp_passwords) t
WHERE t.col_rank = 1
GROUP BY a_col;
Query ID = hadoop_20170810144127_818de1ea-0c47-4a16-a5bf-5b77e3336d69
Total jobs = 1
Launching Job 1 out of 1
Tez session was closed. Reopening...
Session re-established.
Status: Running (Executing on YARN cluster with App id application_1502375367082_0202)
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 .......... container SUCCEEDED 257 257 0 0 0 0
Reducer 2 ...... container SUCCEEDED 53 53 0 0 0 0
Reducer 3 ...... container SUCCEEDED 27 27 0 0 0 0
----------------------------------------------------------------------------------------------
VERTICES: 03/03 [==========================>>] 100% ELAPSED TIME: 105.63 s
----------------------------------------------------------------------------------------------
Moving data to directory hdfs://ip-172-31-43-51.eu-west-1.compute.internal:8020/user/hive/warehouse/s3_hibp_passwords_dedup
OK
Time taken: 112.395 seconds
Now we need to create another hive table, this one will be backed by our DynamoDB table.
> CREATE EXTERNAL TABLE ddb_hibp_passwords (col1 string)
STORED BY 'org.apache.hadoop.hive.dynamodb.DynamoDBStorageHandler'
TBLPROPERTIES ("dynamodb.table.name" = "pwned_passwords", "dynamodb.column.mapping" = "col1:sha1");
OK
Time taken: 0.925 seconds
That's it, we're all ready to go. This is going to take some time, so set it running and go to bed.
> INSERT OVERWRITE TABLE ddb_hibp_passwords
SELECT * FROM s3_hibp_passwords_dedup;
Query ID = hadoop_20170810144407_872afa4b-ca88-4b57-a284-5496fcb0d30f
Total jobs = 1
Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id application_1502375367082_0002)
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 .......... container SUCCEEDED 254 254 0 0 18 0
----------------------------------------------------------------------------------------------
VERTICES: 01/01 [==========================>>] 100% ELAPSED TIME: 59056.94 s
----------------------------------------------------------------------------------------------
OK
Time taken: 59058.426 seconds
hive>
I don't know what happened with the failures, I didn't bother checking. I know I ended up with 319,169,449 hashes in the database, so good enough for me.
Back in the terminal, we can quickly check to see how this is going to work. Note that I shifted the hash to uppercase, the HIBP source data hashes are all uppercase.
davem@wes:~$ SHA1DAVE=$(echo -n dave | sha1sum | tr "[a-z]" "[A-Z]" | awk '{ print $1 }')
davem@wes:~$ echo $SHA1DAVE
BFCDF3E6CA6CEF45543BFBB57509C92AEC9A39FB
davem@wes:~$ aws dynamodb get-item --table-name hibp_passwords --key "{\"sha1\": {\"S\": \"$SHA1DAVE\"}}"
{
"Item": {
"sha1": {
"S": "BFCDF3E6CA6CEF45543BFBB57509C92AEC9A39FB"
}
}
}
real 0.46
user 0.30
sys 0.04
davem@wes:~$
Have fun auditing your passwords.